DeepSeek 将原定于本周早些时候到期的 DeepSeek V4-Pro 的 75% 折扣永久化。现在,中国人工智能实验室小米将缓存输入的 MiMo-V2.5 API 价格削减了 99%。市场上两种最强大的人工智能模型变得更加便宜,而美国实验室则朝着相反的方向发展。
针对房间里的非开发人员的快速解释:当您在浏览器中使用 ChatGPT 或 Claude 时,您需要支付固定订阅费用,或者无需支付任何费用。当一家公司在人工智能模型之上构建产品时,他们会按代币付费,其中一个代币大约相当于一个单词的四分之三。发送的每条消息、生成的每条回复、处理的每份文档:所有这些都以数百万代币的速度加起来。
API 是使这成为可能的原始管道,使应用程序、代理、网站等可以在自己的环境中使用模型。因此,代币定价决定了人工智能驱动的产品在经济上是否可行,还是一个金钱陷阱。
令牌计划是其之上的订阅包装器。您预先购买积分;模型会吃掉它们。小米的计费升级让用户以相同的价格获得5至8倍的代币。 Max 计划的 100 美元现在可为您提供 820 亿个代币,高于 16 亿个。
就上下文而言,820 亿个令牌超过 600 亿个单词。
为什么削减是真实的,而不是营销
小米 MiMo 团队负责人、前 DeepSeek 核心开发人员、DeepSeek-V2 共同开发者罗富力在 X 上发表了技术解释。最大的节省来自于以更智能的方式存储和重用人工智能已经处理过的信息。小米的系统无需重复执行相同的工作,而是可以一次记住更多的数据,大约是以前的五倍。这意味着人工智能需要的计算能力要少得多,从而将存储和处理成本降低约 80%。
Behind the MiMo API Price Reduction:
The deepest price cut, up to 99%, is for Input (Cache Hit). The core reason is our inference framework now supports hierarchical KV cache optimization for SWA. Production inference engine tests show this optimization increases cached token…— Fuli Luo (@_LuoFuli) May 27, 2026
“按照新降低的 API 价格运行,我们的生产推理引擎几乎满负荷运行,我们仍然可以基本上实现收支平衡,”罗写道。 “如果出现更多节省计算和 KV [Key-Value 缓存] 缓存的架构,以及更好的推理基础设施来降低 API 成本,这将在行业中形成良好的良性循环。”
DeepSeek 的架构在同一个地方有所不同。 V4 使用两种交错的注意力类型——一种压缩每 4 个令牌以实现选择性注意力,另一种以最少的计算量压缩每 128 个令牌以实现全局上下文。在 100 万个令牌的上下文中,V4-Pro 的 KV 缓存大小是其前身的 10%,单令牌推理的运行成本是之前的 27%。
结果是该型号比 GPT-5.5 Pro 便宜 98%,且性能具有竞争力。
硅谷的赌注
Claude Opus 4.7 每百万个输入代币的成本为 5 美元,每百万个输出代币的成本为 25 美元。 Anthropic 保持了价目表不变,但附带了一个新的标记器,可以为相同的输入文本生成最多 35% 的标记。所以价格没有涨。您的账单仍然可能。
GPT-5.5,于 4 月底发布,其产出价格刚刚翻了一番,达到每百万代币 30 美元。 Gemini 2.5 Pro 的输入价格为 1.25 美元,输出价格为 10 美元——按照美国标准来说很便宜。
DeepSeek V4-Pro 是一个 1.6 万亿参数模型,只需一小部分计算成本即可为您提供大规模模型的知识库。现在,它永久以每百万代币 0.435 美元的输入和 0.87 美元的输出运行。该模型在 SWE-Verified 上的得分为 80.6%,而 Claude Opus 4.6 的得分为 80.8%——这是衡量真实 GitHub 问题解决情况的基准,而不是精心挑选的演示。具有基本相同编码分数的模型之间的定价差距:输出为 34 倍。
MiMo-V2.5-Pro 在新的削减后,每百万代币的价格为 0.435 美元/0.87 美元。缓存命中率下降至 0.0036 美元。就上下文而言,每个令牌比大多数人为短信中的每个字符支付的费用要便宜。
DeepSeek 和小米并不孤单
此次降价是针对中国车型在此之前已经便宜得多的市场。 MiniMax M2.7 在人工分析的编码基准上与 Claude Opus 进行了较量,每百万代币的投入成本为 0.30 美元,产出成本为 1.20 美元,约为 Opus 4.7 产出率的 5%。
来自 Moonshot AI 的 Kimi K2.5,在 SWE 基准测试上经过验证,运行率为 76.8%,输入为 0.60 美元,输出为 2.50 美元。本季度早些时候,Z.AI 的 GLM-5.1 在关键编码基准测试中击败了 Claude Opus 4.6。 5 月初,四款中国前沿型号在 12 天的时间内发货,均低于 Opus 4.7 每个代币成本的三分之一。
为了更好地可视化,此图表显示了中国模型在性价比方面与美国最受欢迎的三个人工智能提供商(Anthropic、OpenAI 和 Meta)的比较。
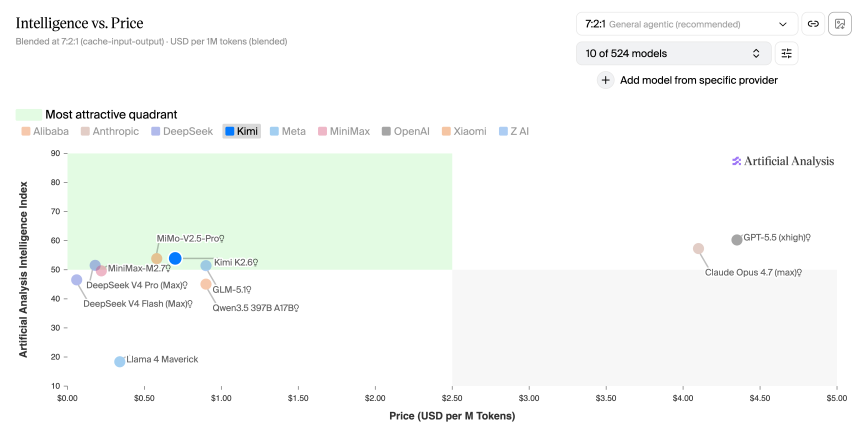 图片:Artificialanalysis.ai
图片:Artificialanalysis.ai
2026 年第二季度,中国和美国前沿型号之间的差距为 15-30 倍,具体取决于您比较的型号 - 这是在任何缓存折扣之前的基线。
本周的削减所做的是进一步缩小生产中实际运行的特定工作负载的差距:具有稳定系统提示的代理管道、文档处理器、检索工具以及不断命中缓存的东西。以每百万缓存输入令牌 0.003625 美元计算,DeepSeek V4-Pro 重复上下文的成本是功能舍入误差。